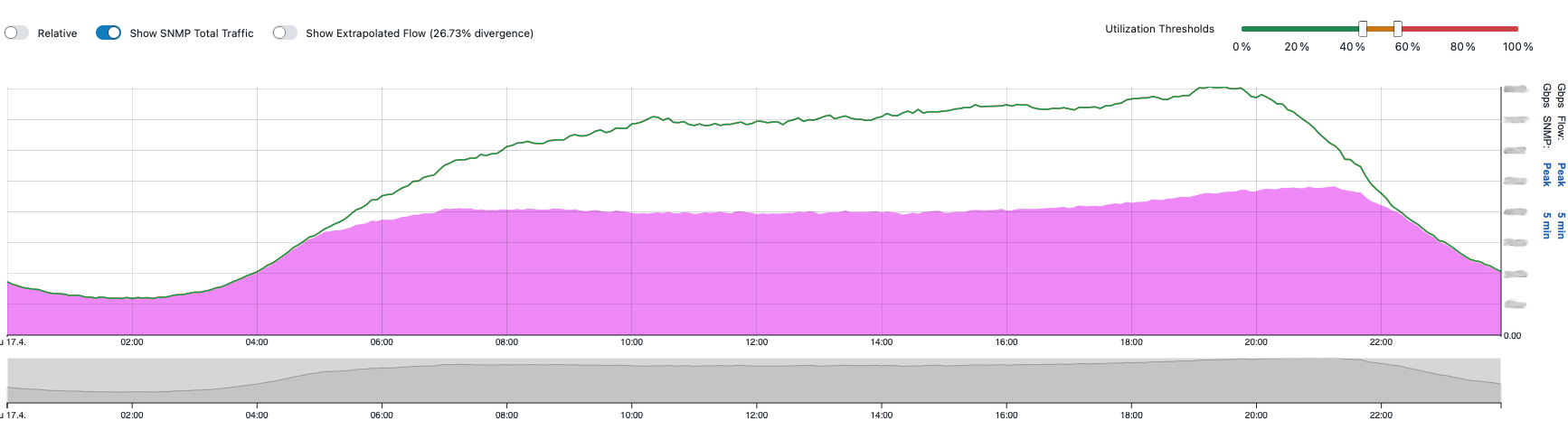
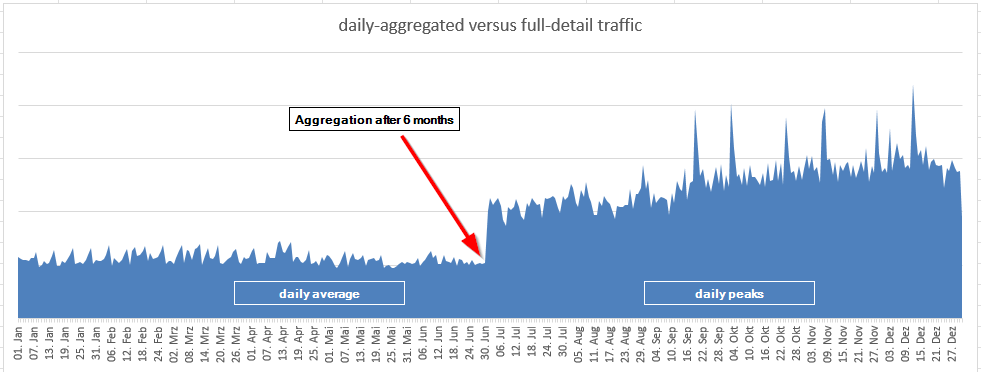
In the world of connectivity, visibility matters. Networks shift, routes change, and the effects often go unnoticed – until they don’t. That’s exactly the gap that the Connectivity Insight Initiative is setting out to close.
Inter.link and BENOCS are joining forces to publish free, practical insights about internet events, traffic patterns, and routing behaviour – all from a European perspective. The goal is simple: give the network community the intelligence it needs to make smarter networking decisions.
What does that look like in practice? Think topology changes that quietly reshape traffic flows, peering shifts between Tier 1 providers, and congestion events that degrade quality before anyone even notices. By combining Inter.link’s global IP infrastructure with BENOCS Analytics, these events become visible – and useful.
The initiative is about curating data and sharing it so the community can make better decisions. In today’s geopolitical climate, a Europen source of internet intelligence isn’t just useful; it’s essential for data sovereignty.
No paid subscription required. Just better insight for everyone.
Follow the Connectivity Insight Initiative on Substack to stay informed.